為各類數據中心提供出...

圖形處理單元 (GPU) 加速器已成為一項關鍵技術。隨著人工智能 (AI) 的進步和數據生成的指數級增長,高性能計算(HPC)和高級圖形工作負載,對強大計算資源的需求從未如此強烈。憑借其并行處理能力,GPU 加速器已成為高效處理這些數據密集型任務的重要工具,從而實現更快的洞察和實時決策。
NVIDIA 是技術領域的領先企業,處于這場 GPU 革命的前沿。他們的 A100 和 H100 GPU 改變了游戲規則,旨在高效處理要求苛刻的計算任務。采用 Ampere 架構的 NVIDIA A100 為加速 AI、HPC 和圖形工作負載樹立了新標準。它提供前所未有的性能和靈活性,使其成為數據中心和研究機構的首選。
另一方面,NVIDIA H100作為該系列的最新產品,它將性能提升到了一個全新的水平。它旨在為 AI、HPC 和圖形提供無與倫比的加速,使用戶能夠解決一些最具挑戰性的計算問題。借助這些 GPU,NVIDIA 繼續塑造技術的未來,突破數字計算的極限。本文比較了 NVIDIA A100 和 H100 GPU,重點介紹了它們的架構、性能基準、AI 功能和能效。
一、比較 A100 和 H100 架構
A100 和 H100 GPU 專為 AI 和 HPC 工作負載而設計,由不同的架構理念驅動。以下是它們之間的比較:
1、NVIDIA A100 的 Ampere 架構
NVIDIA A100 Tensor Core GPU 由革命性的 NVIDIA Ampere 架構,代表了 GPU 技術的重大進步,特別是對于高性能計算(HPC)、人工智能(AI)和數據分析工作負載而言。
該架構以之前的 Tesla V100 GPU 的功能為基礎,增加了許多新功能并顯著提高了性能。
A100 及其 Ampere 架構的主要特點包括:
第三代 Tensor Cores:
這些核心顯著提高了 V100 的吞吐量,并為深度學習和 HPC 數據類型提供全面支持。它們提供新的 Sparsity 功能,可使吞吐量翻倍,提供 TensorFloat-32 運算以加速 FP32 數據處理,以及新的 Bfloat16 混合精度運算。
先進的制造工藝:
為 A100 提供動力的基于 Ampere 架構的 GA100 GPU 采用臺積電 7nm N7 制造工藝制造。它包含 542 億個晶體管,可提供更高的性能和功能。
增強內存和緩存:
A100 具有大型 L1 緩存和共享內存單元,與 V100 相比,每個流式多處理器 (SM) 的總容量是 V100 的 1.5 倍。它還包括 40 GB 的高速 HBM2 內存和 40 MB 的二級緩存,比其前代產品大得多,可確保高計算吞吐量。
多實例 GPU (MIG):
此功能允許 A100 劃分為最多七個單獨的 GPU 實例,用于 CUDA 應用程序,從而為多個用戶提供專用的 GPU 資源。這提高了 GPU 利用率,并在不同客戶端(例如虛擬機、容器和進程)之間提供了服務質量和隔離。
第三代 NVIDIA NVLink:
這種互連技術增強了多 GPU 的可擴展性、性能和可靠性。它顯著增加了 GPU 之間的通信帶寬,并改善了錯誤檢測和恢復功能。

與 NVIDIA Magnum IO 和 Mellanox 解決方案的兼容性:
A100 與這些解決方案完全兼容,可最大限度地提高多 GPU 多節點加速系統的 I/O 性能并促進廣泛的工作負載。
通過 SR-IOV 支持 PCIe Gen 4:
通過支持 PCIe Gen 4,A100 將 PCIe 3.0/3.1 帶寬增加了一倍,這有利于與現代 CPU 和快速網絡接口的連接。它還支持單根輸入/輸出虛擬化,允許為多個進程或虛擬機提供共享和虛擬化的 PCIe 連接。
異步復制與屏障特點:
A100 包含新的異步復制和屏障指令,可優化數據傳輸和同步并降低功耗。這些功能提高了數據移動和計算重疊的效率。
任務圖加速:
A100 中的 CUDA 任務圖使向 GPU 提交工作的模型更加高效,從而提高了應用程序的效率和性能。
增強型 HBM2 DRAM 子系統:
A100 繼續提升 HBM2 內存技術的性能和容量,這對于不斷增長的 HPC、AI 和分析數據集至關重要。
NVIDIA A100 采用 Ampere 架構,代表一種先進而強大的 GPU 解決方案,旨在滿足現代 AI、HPC 和數據分析應用程序的苛刻要求。
H100 比 A100 快多少?
H100 GPU 最高可達快九倍用于 AI 訓練,推理速度比 A100 快 30 倍。在運行 FlashAttention-2 訓練時,NVIDIA H100 80GB SXM5 比 NVIDIA A100 80GB SXM4 快兩倍。
2、NVIDIA H100 的 Hopper 架構
NVIDIA 的 H100 利用創新Hopper 架構專為 AI 和 HPC 工作負載而設計。該架構的特點是專注于 AI 應用的效率和高性能。Hopper 架構的主要特點包括:
第四代 Tensor Cores:
這些核心的性能比上一代快 6 倍,并針對對 AI 計算至關重要的矩陣運算進行了優化。
變壓器引擎:
該專用引擎可加速人工智能的訓練和推理,顯著提高大型語言模型處理的速度。
HBM3 內存:
H100 是第一款配備 HBM3 內存的 GPU,帶寬加倍,性能增強。
提高處理速度:
H100 具有強大的計算能力,IEEE FP64 和 FP32 速率比其前代產品快 3 倍。
DPX 說明:
這些新指令提高了動態規劃算法的性能,這對于基因組學和機器人技術的應用至關重要。
多實例 GPU 技術:
這項第二代技術可以安全且高效地分區 GPU,滿足不同的工作負載需求。
先進的互連技術:
H100 采用了第四代 NVIDIA NVLink 和 NVSwitch,確保在多 GPU 設置中實現卓越的連接性和帶寬。異步執行和線程塊集群:這些功能可優化數據處理效率,這對于復雜的計算任務至關重要。
分布式共享內存:
該功能促進了SM之間高效的數據交換,提高了整體數據處理速度。
H100 采用 Hopper 架構,標志著 GPU 技術的重大進步。它體現了硬件的不斷發展,旨在滿足 AI 和 HPC 應用日益增長的需求。
二、性能基準
性能基準測試可以提供有關 NVIDIA A100 和 H100 等 GPU 加速器功能的寶貴見解。這些基準測試包括不同精度的每秒浮點運算次數 (FLOPS) 和特定于 AI 的指標,可以幫助我們了解每個 GPU 的優勢所在,特別是在科學研究、AI 建模和圖形渲染等實際應用中。
1、NVIDIA A100 性能基準
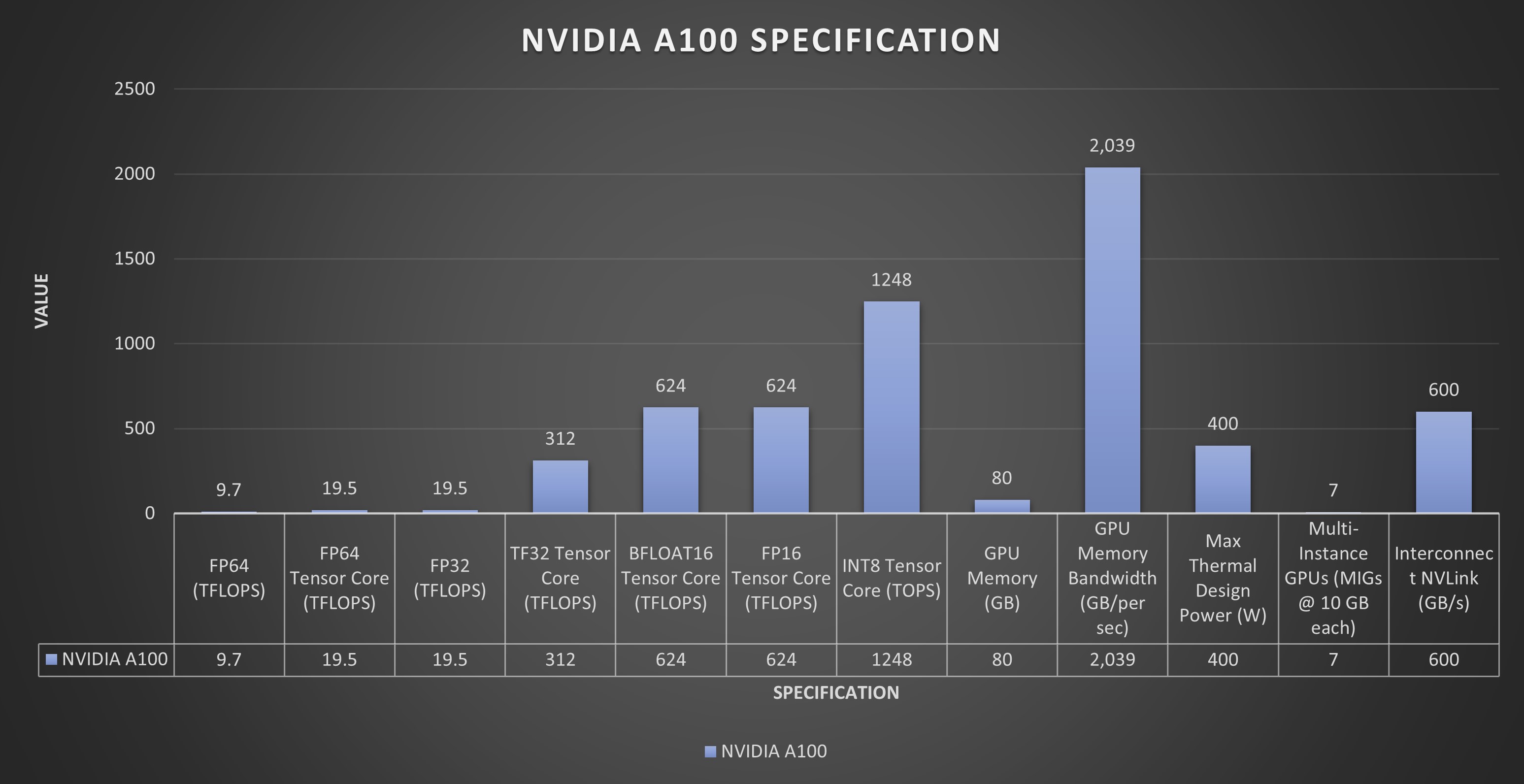
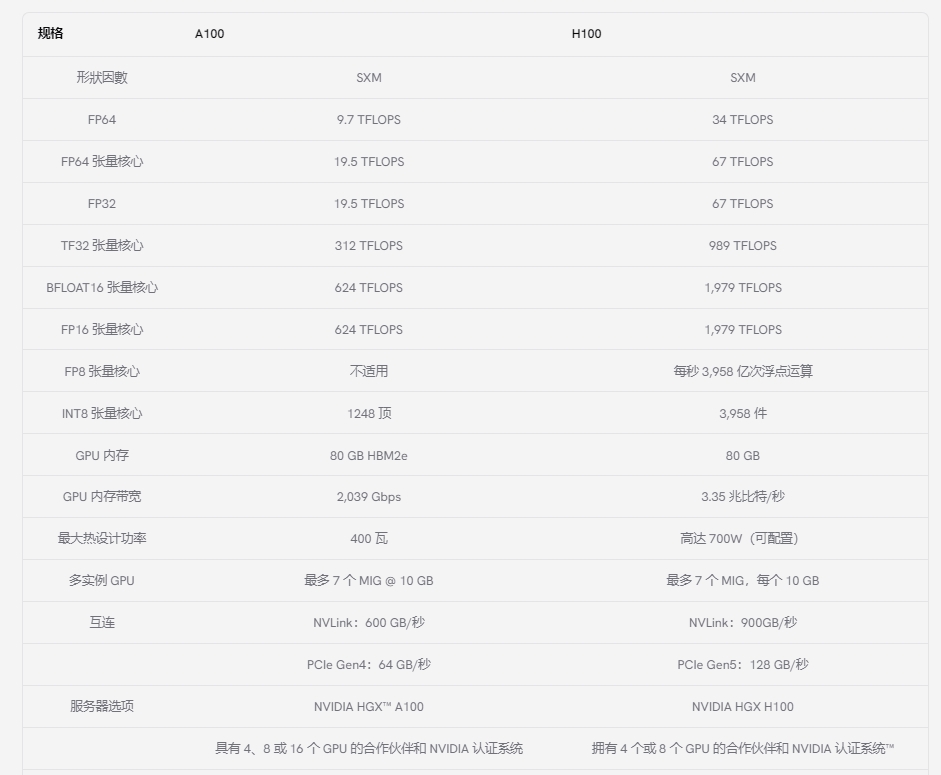
NVIDIA 的 A100 GPU 在各種基準測試中均表現出色。在浮點運算方面,A100 為雙精度 (FP64) 提供高達 19.5 TFLOPS 的浮點運算能力,為單精度 (FP32) 提供高達 39.5 TFLOPS 的浮點運算能力。這種高計算吞吐量對于需要高精度的 HPC 工作負載(例如科學模擬和數據分析)至關重要。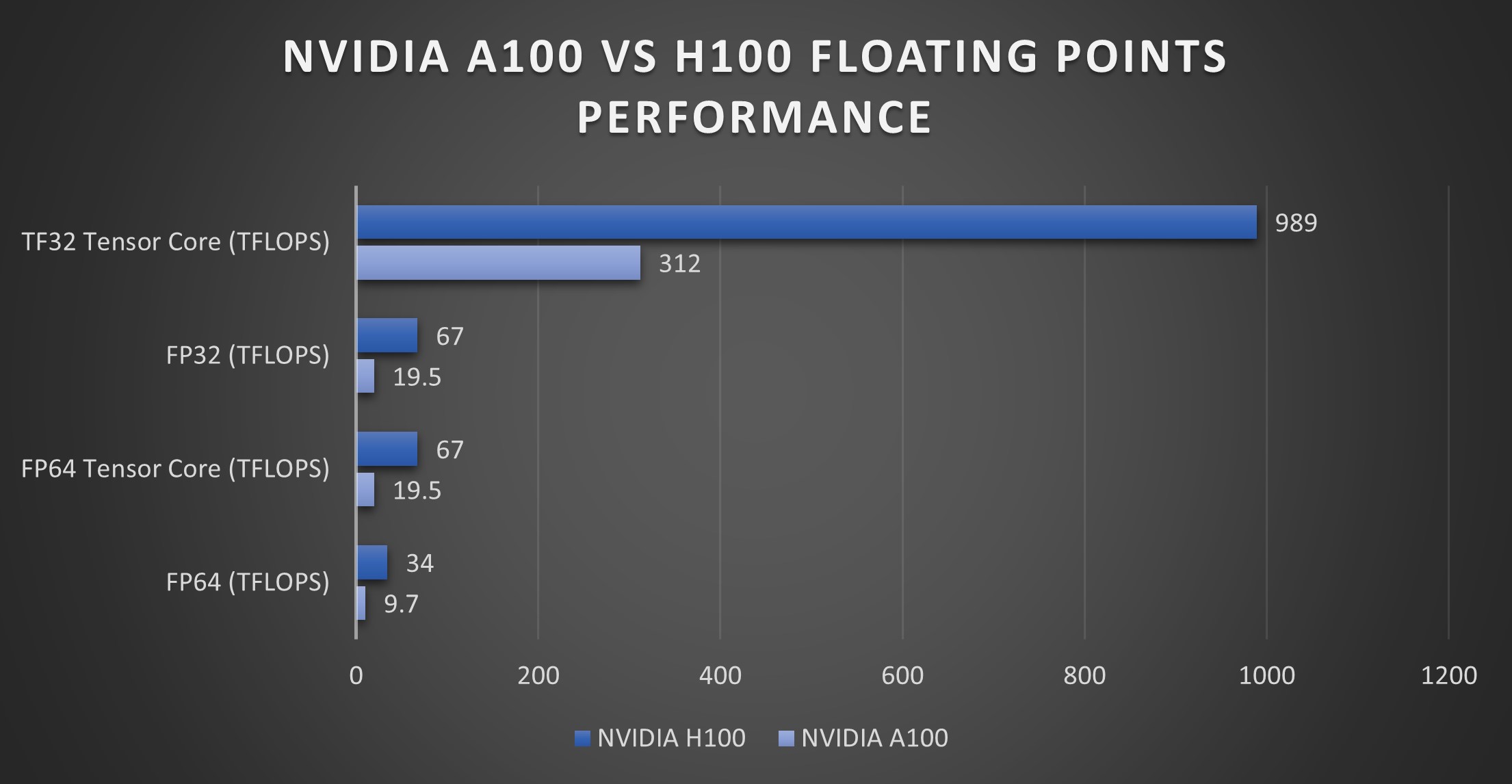
此外,A100 在張量運算方面表現出色,這對 AI 計算至關重要。張量核心可為 FP16 精度提供高達 312 TFLOPS 的性能,為張量浮點 32 (TF32) 運算提供高達 156 TFLOPS 的性能。這使得 A100 成為 AI 建模和深度學習任務的強大工具,這些任務通常需要大規模矩陣運算,并受益于張量核心提供的加速。
2、NVIDIA H100 性能基準
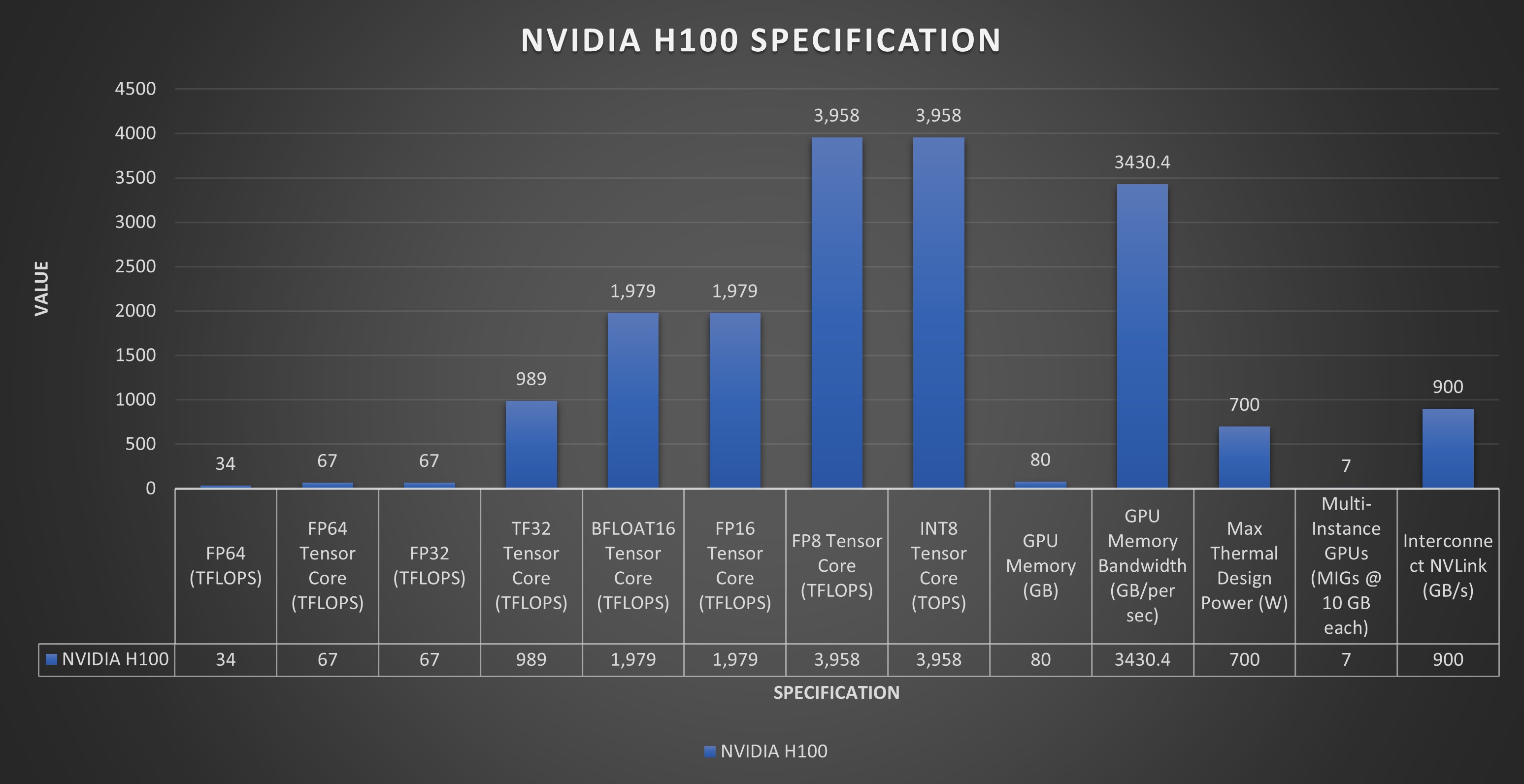
NVIDIA H100 GPU 在各種基準測試中均展現出卓越的性能。在浮點運算方面,雖然這里沒有提供雙精度 (FP64) 和單精度 (FP32) 的具體 TFLOPS 值,但 H100 旨在顯著提高計算吞吐量,這對于科學模擬和數據分析等 HPC 應用至關重要。
張量運算對于 AI 計算至關重要,而 H100 的第四代 Tensor Core 預計將比前幾代產品實現大幅性能提升。這些進步使 H100 成為一款功能極其強大的 AI 建模和深度學習工具,得益于大規模矩陣運算和 AI 特定任務的效率和速度提升。
三、人工智能和機器學習能力
人工智能和機器學習功能是現代 GPU 的關鍵組成部分,NVIDIA 的 A100和 H100 提供獨特的功能,以增強其在 AI 工作負載中的性能。
1、張量核心:
NVIDIA A100 GPU 采用 Ampere 架構,在 AI 和機器學習方面取得了重大進展。A100 集成了第三代 Tensor Core,性能比 NVIDIA 的 Volta 架構(上一代)高出 20 倍。這些 Tensor Core 支持各種混合精度計算,例如 Tensor Float (TF32),從而提高了 AI 模型訓練和推理效率。
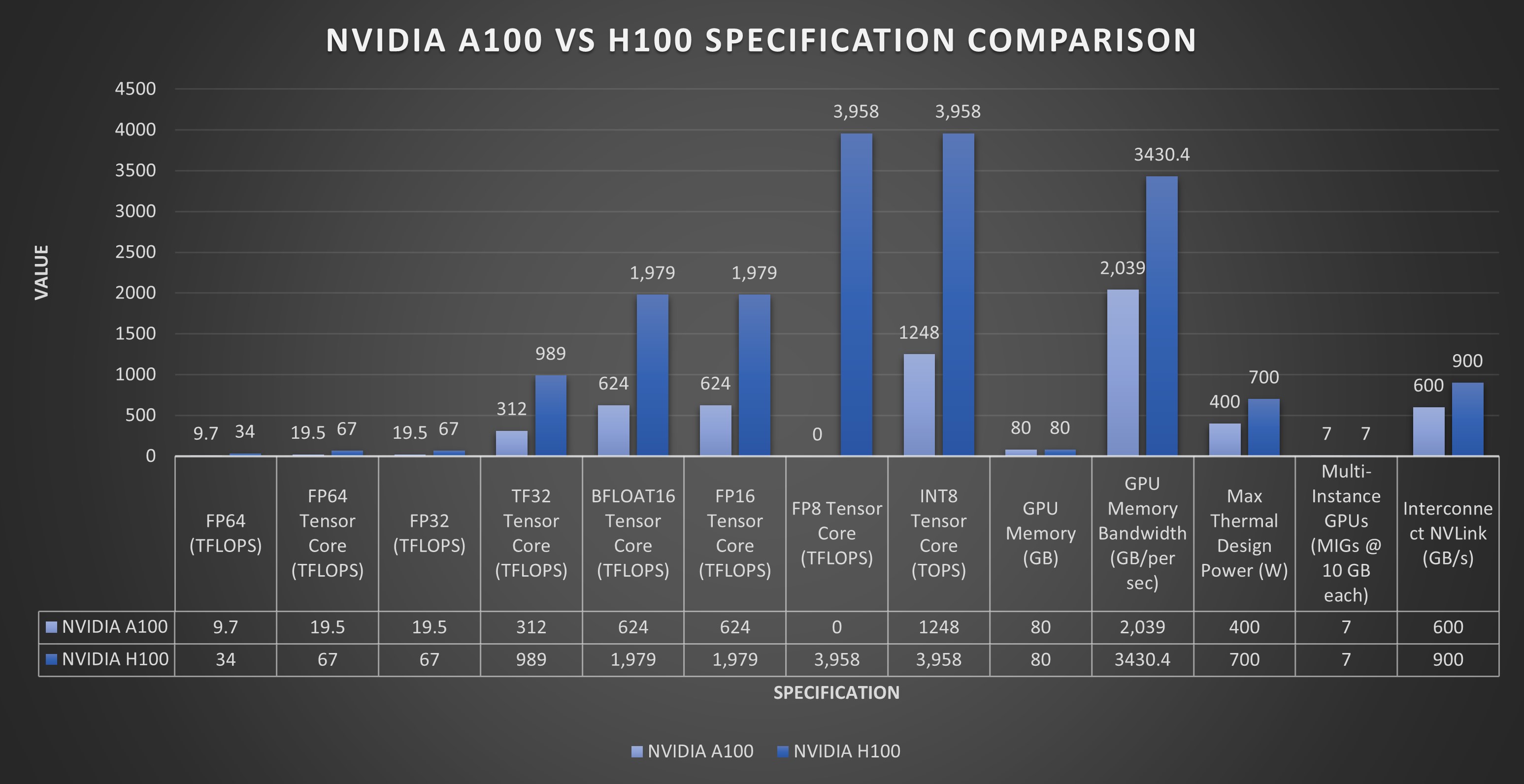
另一方面,NVIDIA H100 GPU 也代表了 AI 和 HPC 性能的重大飛躍。它具有新的第四代 Tensor Core,速度比 A100 中的速度快 6 倍。與 A100 相比,這些核心每個 SM 的矩陣乘法累加 (MMA) 計算速率提高了一倍,使用新的 FP8 數據類型時,增益甚至更大。此外,H100 的 Tensor Core 專為更廣泛的 AI 和 HPC 任務而設計,并具有更高效的數據管理功能。
2、多實例 GPU (MIG) 技術:
A100 引入了 MIG 技術,允許將單個 A100 GPU 劃分為多達七個獨立實例。該技術優化了 GPU 資源的利用率,支持在單個 A100 GPU 上同時運行多個網絡或應用程序。A100 40GB 版本最多可以為每個 MIG 實例分配 5GB,而 80GB 版本則將容量翻倍至每個實例 10GB。
然而,H100 采用了第二代 MIG 技術,每個 GPU 實例的計算能力比 A100 提高了約 3 倍,內存帶寬提高了近 2 倍。這一進步進一步提高了 GPU 加速基礎設施的利用率。
3、H100 的新功能:
H100 GPU 包含一個新的轉換引擎,它使用 FP8 和 FP16 精度來增強 AI 訓練和推理,特別是對于大型語言模型。與 A100 相比,該引擎可以提供高達 9 倍的 AI 訓練速度和 30 倍的 AI 推理速度。H100 還引入了 DPX 指令,提供高達提升 7 倍的性能與 Ampere GPU 相比,動態規劃算法更勝一籌。

總的來說,這些改進為 H100 提供了大約峰值計算吞吐量提高 6 倍。A100 的推出,標志著對苛刻的計算工作負載的重大進步。NVIDIA A100 和 H100 GPU 代表了 AI 和機器學習能力的重大進步,每一代都引入了創新功能,例如先進的 Tensor Cores 和 MIG 技術。H100 建立在 A100 的 Ampere 架構的基礎上,進一步增強了 AI 處理能力和整體性能。
四、A100 或 H100 值得購買嗎?
A100 或 H100 是否值得購買取決于用戶的具體需求。這兩款 GPU 都非常適合高性能計算 (HPC) 和人工智能 (AI) 工作負載。然而,H100 在 AI 訓練和推理任務中速度明顯更快。雖然 H100 更貴,但其卓越的速度可能值得特定用戶花費。
五、電力效率和環境影響
NVIDIA 的 A100 和 H100 等 GPU 的熱設計功率 (TDP) 等級提供了有關其功耗的寶貴見解,這對性能和環境影響都有影響。
1、GPU 熱設計功耗:
A100 GPU 的 TDP 因型號而異。配備 40 GB HBM2 內存的標準 A100 的 TDP 為 250W。但是,A100 的 SXM 變體具有更高的 TDP,為 400W,而配備 80 GB 內存的 SXM 變體的 TDP 則增加到 700W。這表明 A100 需要強大的冷卻解決方案,并且功耗相當大,具體功耗可能因具體型號和工作負載而異。
H100 PCIe 版本的 TDP 為 350W,接近其前身 A100 80GB PCIe 的 300W TDP。然而,H100 SXM5 支持高達 700W 的 TDP。盡管 TDP 如此之高,但 H100 GPU 比 A100 GPU 更節能,與 A100 80GB PCIe 和 SXM4 前身相比,FP8 FLOPS/W 分別增加了 4 倍和近 3 倍。這表明,雖然 H100 的功耗可能很高,但與 A100 相比,它的能效更高,尤其是在每瓦性能方面。
2、電源效率比較:
雖然 A100 GPU 的運行功率較低,為 400 瓦,但在某些工作負載下,其功率可低至 250 瓦,這表明與 H100 相比,其整體能效更高。另一方面,H100 的功耗更高,在某些情況下可高達 500 瓦。這一比較凸顯出,雖然這兩款 GPU 都很強大且功能豐富,但它們的功耗和效率存在很大差異,而 A100 整體上更節能。
雖然 NVIDIA A100 和 H100 GPU 都功能強大,但它們的 TDP 和能效特性不同。A100 的功耗因型號而異,但總體而言,它往往更節能。H100(尤其是其高端版本)的 TDP 更高,但每瓦性能更高,尤其是在 AI 和深度學習任務中。這些差異是必須考慮的,尤其是考慮到環境影響和對強大冷卻解決方案的需求。
無論您選擇 A100 經過驗證的效率還是 H100 的先進功能,捷智算平臺都會為您提供卓越計算性能所需的資源。











